Kernel Launcher
Kernel Launcher is a C++ library designed to dynamically compile CUDA kernels at runtime (using NVRTC) and to launch them in a type-safe manner using C++ magic. Runtime compilation offers two significant advantages:
Kernels that have tunable parameters (block size, elements per thread, loop unroll factors, etc.) where the optimal configuration depends on dynamic factors such as the GPU type and problem size.
Improve performance by injecting runtime values as compile-time constant values into kernel code (dimensions, array strides, weights, etc.).
Kernel Tuner Integration
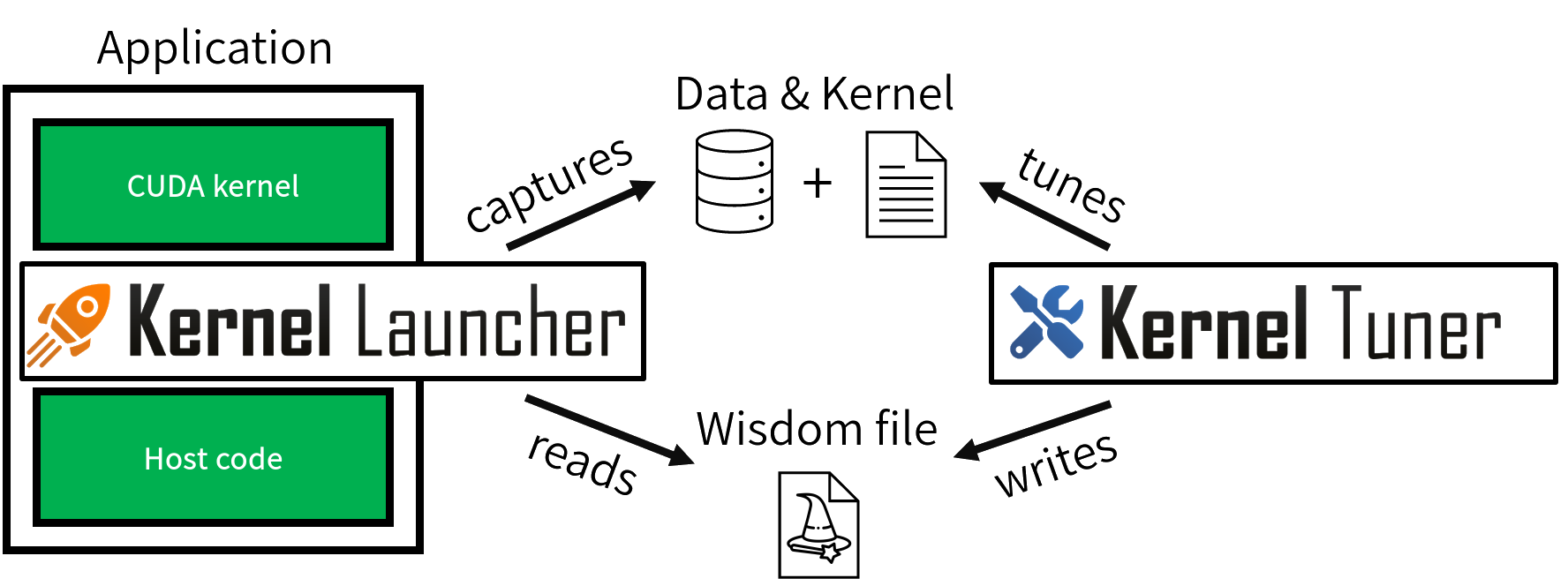
The tight integration of Kernel Launcher with Kernel Tuner ensures that kernels are highly optimized, as illustrated in the image above. Kernel Launcher can capture kernel launches within your application at runtime. These captured kernels can then be tuned by Kernel Tuner and the tuning results are saved as wisdom files. These wisdom files are used by Kernel Launcher during execution to compile the tuned kernel at runtime.
See Wisdom Files for an example of how this works in practise.
Basic Example
This section presents a simple code example illustrating how to use the Kernel Launcher. For a more detailed example, refer to Guides.
Consider the following CUDA kernel for vector addition.
This kernel has a template parameter T and a tunable parameter ELEMENTS_PER_THREAD.
1template <typename T>
2__global__
3void vector_add(int n, T* C, const T* A, const T* B) {
4 for (int k = 0; k < ELEMENTS_PER_THREAD; k++) {
5 int i = blockIdx.x * ELEMENTS_PER_THREAD * blockDim.x + k * blockDim.x + threadIdx.x;
6
7 if (i < n) {
8 C[i] = A[i] + B[i];
9 }
10 }
11}
The following C++ snippet demonstrates how to use the Kernel Launcher in the host code:
1#include "kernel_launcher.h"
2
3int main() {
4 // Namespace alias.
5 namespace kl = kernel_launcher;
6
7 // Create a kernel builder
8 kl::KernelBuilder builder("vector_add", "vector_add_kernel.cu");
9
10 // Define the variables that can be tuned for this kernel.
11 kl::ParamExpr threads_per_block = builder.tune("block_size", {32, 64, 128, 256, 512, 1024});
12 kl::ParamExpr elements_per_thread = builder.tune("elements_per_thread", {1, 2, 4, 8});
13
14 // Set kernel properties such as block size, grid divisor, template arguments, etc.
15 builder
16 .problem_size(kl::arg0)
17 .block_size(threads_per_block)
18 .grid_divisors(threads_per_block * elements_per_thread)
19 .template_args(kl::type_of<float>())
20 .define("ELEMENTS_PER_THREAD", elements_per_thread);
21
22 // Define the kernel
23 kl::WisdomKernel vector_add_kernel(builder);
24
25 // Initialize CUDA memory. This is outside the scope of kernel_launcher.
26 unsigned int n = 1000000;
27 float *dev_A, *dev_B, *dev_C;
28 /* cudaMalloc, cudaMemcpy, ... */
29
30 // Launch the kernel! Note that kernel is compiled on the first call.
31 // The grid size and block size do not need to be specified, they are
32 // derived from the kernel specifications.
33 vector_add_kernel(n, dev_C, dev_A, dev_B);
34}