Design documentation¶
This section provides detailed information about the design and internals of the Kernel Tuner. This information is mostly relevant for developers.
The Kernel Tuner is designed to be extensible and support different search and execution strategies. The current architecture of the Kernel Tuner can be seen as:
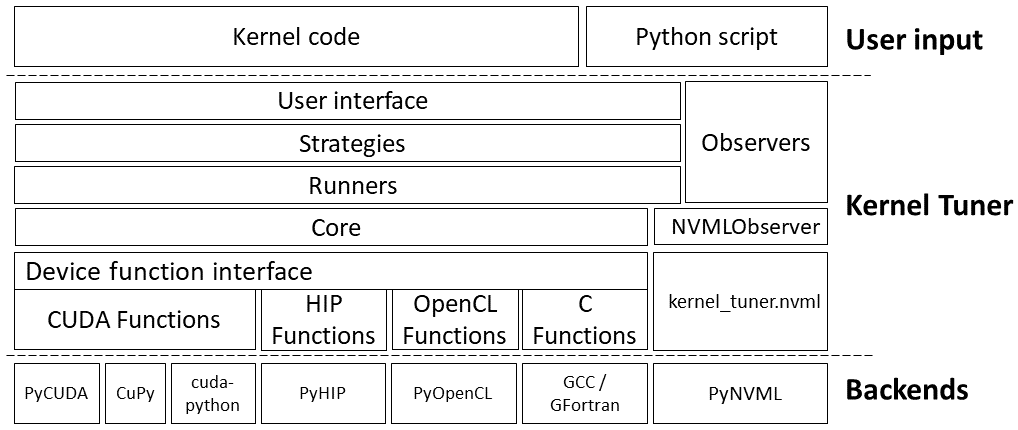
At the top we have the kernel code and the Python script that tunes it, which uses any of the main functions exposed in the user interface.
The strategies are responsible for iterating over and searching through
the search space. The default strategy is brute_force, which
iterates over all valid kernel configurations in the search space.
random_sample simply takes a random sample of the search space. More
advanced strategies are continuously being implemented and improved in
Kernel Tuner. The full list of supported strategies and how to use these
is explained in the API Documentation, see the options strategy and
strategy_options.
The runners are responsible for compiling and benchmarking the kernel configurations selected by the strategy. The sequential runner is currently the only supported runner, which does exactly what its name says. It compiles and benchmarks configurations using a single sequential Python process. Other runners are foreseen in future releases.
The runners are implemented on top of the core, which implements a
high-level Device Interface,
which wraps all the functionality for compiling and benchmarking
kernel configurations based on the low-level Device Function Interface.
Currently, we have
five different implementations of the device function interface, which
basically abstracts the different backends into a set of simple
functions such as ready_argument_list which allocates GPU memory and
moves data to the GPU, and functions like compile, benchmark, or
run_kernel. The functions in the core are basically the main
building blocks for implementing runners.
The observers are explained in Observers.
At the bottom, the backends are shown. PyCUDA, CuPy, cuda-python, PyOpenCL and HIP Python are for tuning either CUDA, OpenCL, or HIP kernels. The CompilerFunctions implementation can call any compiler, typically NVCC or GCC is used. There is limited support for tuning Fortran kernels. This backend was created not just to be able to tune C functions, but in particular to tune C functions that in turn launch GPU kernels.
The rest of this section contains the API documentation of the modules discussed above. For the documentation of the user API see the API Documentation.
SearchSpace¶
The SearchSpace object is central to Kernel Tuner as it represents the search space that is to be explored by the search strategies.
kernel_tuner.searchspace.Searchspace¶
- class kernel_tuner.searchspace.Searchspace(tune_params: dict, restrictions, max_threads: int, block_size_names=['block_size_x', 'block_size_y', 'block_size_z'], defer_construction=False, build_neighbors_index=False, neighbor_method=None, from_cache: dict | None = None, framework='PythonConstraint', solver_method='PC_OptimizedBacktrackingSolver', path_to_ATF_cache: Path | None = None)¶
Class that provides the search space to strategies.
- __init__(tune_params: dict, restrictions, max_threads: int, block_size_names=['block_size_x', 'block_size_y', 'block_size_z'], defer_construction=False, build_neighbors_index=False, neighbor_method=None, from_cache: dict | None = None, framework='PythonConstraint', solver_method='PC_OptimizedBacktrackingSolver', path_to_ATF_cache: Path | None = None) None¶
Build a searchspace using the variables and constraints.
- Optionally build the neighbors index - only faster if you repeatedly look up neighbors. Methods:
strictly-adjacent: differs +1 or -1 parameter index value for each parameter adjacent: picks closest parameter value in both directions for each parameter Hamming: any parameter config with 1 different parameter value is a neighbor Hamming-adjacent: differs by closest parameter value for exactly 1 parameter.
Optionally sort the searchspace by the order in which the parameter values were specified. By default, sort goes from first to last parameter, to reverse this use sort_last_param_first. Optionally an imported cache can be used instead with from_cache, in which case the tune_params, restrictions and max_threads arguments can be set to None, and construction is skipped. Optionally construction can be deffered to a later time by setting defer_construction to True, in which case the searchspace is not built on instantiation (experimental).
- are_neighbors_indices_cached(param_config: tuple, neighbor_method=None) bool¶
Returns true if the neighbor indices are in the cache, false otherwise.
- get_LHS_sample(num_samples: int) List[tuple]¶
Get a distributed random sample of parameter configurations.
- get_LHS_sample_indices(num_samples: int) List[int]¶
Get a Latin Hypercube sample of parameter configuration indices.
- get_distributed_random_sample(num_samples: int, sampling_factor=10) List[tuple]¶
Get a distributed random sample of parameter configurations.
- get_distributed_random_sample_indices(num_samples: int, sampling_factor=10) List[int]¶
Get a distributed random sample of parameter configuration indices. Note: get_LHS_sample_indices is likely faster and better distributed.
- get_list_dict() dict¶
Get the internal dictionary.
- get_list_numpy() ndarray¶
Get the parameter space list as a NumPy array of tuples with mixed types.
Rarely faster or more convenient than get_list_param_indices_numpy or get_list_numpy_numeric. Initializes the NumPy array if not yet done.
- Returns:
the NumPy array.
- get_list_numpy_numeric() ndarray¶
Get the parameter space list as a 2D NumPy array of numeric values.
This is a view of the NumPy array returned by get_list_numpy, but with only numeric values. If the searchspace contains non-numeric values, their index will be used instead.
- Returns:
the NumPy array.
- get_list_param_indices_numpy() ndarray¶
Get the parameter space list as a 2D NumPy array of parameter value indices.
Same as mapping get_param_indices over the searchspace, but faster. Assumes that the parameter configs have the same order as tune_params.
- Returns:
the NumPy array.
- get_list_param_indices_numpy_max()¶
Get the maximum possible value in the numpy list of parameter indices.
- get_list_param_indices_numpy_min()¶
Get the minimum possible value in the numpy list of parameter indices.
- get_neighbors(param_config: tuple, neighbor_method=None, build_full_cache=False) List[tuple]¶
Get the neighbors for a parameter configuration.
- get_neighbors_indices(param_config: tuple, neighbor_method=None, build_full_cache=False) List[int]¶
Get the neighbors indices for a parameter configuration, cached if requested before.
- get_neighbors_indices_no_cache(param_config: tuple, neighbor_method=None, build_full_cache=False) List[int]¶
Get the neighbors indices for a parameter configuration (does not check running cache, useful when mixing neighbor methods).
- get_neighbors_no_cache(param_config: tuple, neighbor_method=None) List[tuple]¶
Get the neighbors for a parameter configuration (does not check running cache, useful when mixing neighbor methods).
- get_param_config_from_numeric(param_config: tuple) tuple¶
Get the actual parameter configuration values from a numeric representation of the parameter configuration as in get_list_numpy_numeric.
- get_param_config_from_param_indices(param_indices: tuple) tuple¶
Get the parameter configuration from the given parameter indices.
- get_param_config_index(param_config: tuple | any)¶
Lookup the index for a parameter configuration, returns None if not found.
- get_param_configs_at_indices(indices: List[int]) List[tuple]¶
Get the param configs at the given indices.
- get_param_indices(param_config: tuple) tuple¶
For each parameter value in the param config, find the index in the tunable parameters.
- get_param_indices_lower_bounds() ndarray¶
Get the lower bounds of the parameter indices after restrictions.
- get_param_indices_upper_bounds() ndarray¶
Get the upper bounds of the parameter indices after restrictions.
- get_param_neighbors(param_config: tuple, index: int, neighbor_method: str, randomize: bool) list¶
Get the neighboring parameters at an index.
- get_partial_neighbors_indices(param_config: tuple, neighbor_method=None) List[tuple]¶
Get the partial neighbors for a parameter configuration.
- get_random_neighbor(param_config: tuple, neighbor_method=None, use_partial_cache=True) tuple¶
Get an approximately random neighbor for a parameter configuration. Much faster than taking a random choice of all neighbors, but does not build full cache.
- get_random_sample(num_samples: int) List[tuple]¶
Get the parameter configurations for a random, non-conflicting sample (caution: not unique in consecutive calls).
- get_random_sample_indices(num_samples: int) ndarray¶
Get the list indices for a random, non-conflicting sample.
- get_tensorspace()¶
Get the searchspace encoded in a Tensor. To use a non-default dtype or device, call initialize_tensorspace first.
- get_tensorspace_bounds()¶
Get the bounds to the tensorspace parameters, returned as a 2 x d dimensional tensor, and the indices of the parameters.
- get_tensorspace_categorical_dimensions()¶
Get the a list of the categorical dimensions in the tensorspace.
- get_true_tunable_params() dict¶
Get the tunable parameters that are actually tunable, i.e. not constant after restrictions.
- get_tune_params_pyatf(block_size_names: list | None = None, max_threads: int | None = None)¶
Convert the tune_params and restrictions to pyATF tunable parameters.
- has_tensorspace() bool¶
Check if the tensorspace has been initialized.
- initialize_tensorspace(dtype=None, device=None)¶
Encode the searchspace in a Tensor. Save the mapping. Call this function directly to control the precision or device used.
- is_param_config_valid(param_config: tuple) bool¶
Returns whether the parameter config is valid (i.e. is in the searchspace after restrictions).
- order_param_configs(param_configs: List[tuple], order: List[int], randomize_in_params=True) List[tuple]¶
Order a list of parameter configurations based on the indices of the parameters given, starting at 0. If randomize_params is true, the order within parameters is shuffled.
- param_config_to_tensor(param_config: tuple)¶
Convert from a parameter configuration to a Tensor.
- pop_random_partial_neighbor(param_config: tuple, neighbor_method=None, threshold=2) tuple¶
Pop a random partial neighbor for a given a parameter configuration if there are at least threshold neighbors.
- sorted_list(sort_last_param_first=False)¶
Returns list of parameter configs sorted based on the order in which the parameter values were specified.
- Parameters:
sort_last_param_first – By default, sort goes from first to last parameter, to reverse this use sort_last_param_first
- tensor_to_param_config(tensor)¶
Convert from a Tensor to a parameter configuration.
- to_ax_searchspace()¶
Convert this searchspace to an Ax SearchSpace.
Strategies¶
Strategies are explained in Optimization strategies.
Many of the strategies use helper functions that are collected in kernel_tuner.strategies.common.
kernel_tuner.strategies.common¶
Module for functionality that is commonly used throughout the strategies.
- class kernel_tuner.strategies.common.CostFunc(searchspace: Searchspace, tuning_options, runner, *, scaling=False, snap=True, return_invalid=False, invalid_value=1.7976931348623157e+308)¶
Class encapsulating the CostFunc method.
- eval_all(xs, check_restrictions=True)¶
Cost function used by almost all strategies.
- get_bounds()¶
Create a bounds array from the tunable parameters.
- get_bounds_x0_eps()¶
Compute bounds, x0 (the initial guess), and eps.
- get_start_pos()¶
Get starting position for optimization.
- kernel_tuner.strategies.common.get_options(strategy_options, options, unsupported=None)¶
Get the strategy-specific options or their defaults from user-supplied strategy_options.
- kernel_tuner.strategies.common.get_strategy_docstring(name, strategy_options)¶
Generate docstring for a ‘tune’ method of a strategy.
- kernel_tuner.strategies.common.make_strategy_options_doc(strategy_options)¶
Generate documentation for the supported strategy options and their defaults.
- kernel_tuner.strategies.common.scale_from_params(params, tune_params, eps)¶
Helper func to do the inverse of the ‘unscale’ function.
- kernel_tuner.strategies.common.setup_method_arguments(method, bounds)¶
Prepare method specific arguments.
- kernel_tuner.strategies.common.setup_method_options(method, tuning_options)¶
Prepare method specific options.
- kernel_tuner.strategies.common.snap_to_nearest_config(x, tune_params)¶
Helper func that for each param selects the closest actual value.
- kernel_tuner.strategies.common.unscale_and_snap_to_nearest(x, tune_params, eps)¶
Helper func that snaps a scaled variable to the nearest config.
- kernel_tuner.strategies.common.unscale_and_snap_to_nearest_valid(x, params, searchspace, eps)¶
Helper func to snap to the nearest valid configuration
Runners¶
kernel_tuner.runners.sequential.SequentialRunner¶
- class kernel_tuner.runners.sequential.SequentialRunner(kernel_source, kernel_options, device_options, iterations, observers)¶
SequentialRunner is used for tuning with a single process/thread.
- __init__(kernel_source, kernel_options, device_options, iterations, observers)¶
Instantiate the SequentialRunner.
- Parameters:
kernel_source (kernel_tuner.core.KernelSource) – The kernel source
kernel_options (kernel_tuner.interface.Options) – A dictionary with all options for the kernel.
device_options (kernel_tuner.interface.Options) – A dictionary with all options for the device on which the kernel should be tuned.
iterations (int) – The number of iterations used for benchmarking each kernel instance.
- get_device_info()¶
Return the backend used by this runner.
- run(parameter_space, tuning_options)¶
Iterate through the entire parameter space using a single Python process.
- Parameters:
parameter_space (iterable) – The parameter space as an iterable.
tuning_options (kernel_tuner.interface.Options) – A dictionary with all options regarding the tuning process.
- Returns:
A list of dictionaries for executed kernel configurations and their execution times.
- Return type:
dict()
kernel_tuner.runners.sequential.SimulationRunner¶
- class kernel_tuner.runners.simulation.SimulationRunner(kernel_source, kernel_options, device_options, iterations, observers)¶
SimulationRunner is used for tuning with a single process/thread.
- __init__(kernel_source, kernel_options, device_options, iterations, observers)¶
Instantiate the SimulationRunner.
- Parameters:
kernel_source (kernel_tuner.core.KernelSource) – The kernel source
kernel_options (kernel_tuner.interface.Options) – A dictionary with all options for the kernel.
device_options (kernel_tuner.interface.Options) – A dictionary with all options for the device on which the kernel should be tuned.
iterations (int) – The number of iterations used for benchmarking each kernel instance.
- get_device_info()¶
Return the backend used by this runner.
- run(parameter_space, tuning_options)¶
Iterate through the entire parameter space using a single Python process.
- Parameters:
parameter_space (iterable) – The parameter space as an iterable.
tuning_options (kernel_tuner.iterface.Options) – A dictionary with all options regarding the tuning process.
- Returns:
A list of dictionaries for executed kernel configurations and their execution times.
- Return type:
dict()
Backends¶
kernel_tuner.backends.pycuda.PyCudaFunctions¶
- class kernel_tuner.backends.pycuda.PyCudaFunctions(device=0, iterations=7, compiler_options=None, observers=None)¶
Class that groups the CUDA functions on maintains state about the device.
- __init__(device=0, iterations=7, compiler_options=None, observers=None)¶
Instantiate PyCudaFunctions object used for interacting with the CUDA device.
Instantiating this object will inspect and store certain device properties at runtime, which are used during compilation and/or execution of kernels by the kernel tuner. It also maintains a reference to the most recently compiled source module for copying data to constant memory before kernel launch.
- Parameters:
device (int) – Number of CUDA device to use for this context
iterations (int) – Number of iterations used while benchmarking a kernel, 7 by default.
- compile(kernel_instance)¶
Call the CUDA compiler to compile the kernel, return the device function.
- Parameters:
kernel_name (string) – The name of the kernel to be compiled, used to lookup the function after compilation.
kernel_string (string) – The CUDA kernel code that contains the function kernel_name
- Returns:
An CUDA kernel that can be called directly.
- Return type:
pycuda.driver.Function
- copy_constant_memory_args(cmem_args)¶
Adds constant memory arguments to the most recently compiled module.
- Parameters:
cmem_args (dict( string: numpy.ndarray, ... )) – A dictionary containing the data to be passed to the device constant memory. The format to be used is as follows: A string key is used to name the constant memory symbol to which the value needs to be copied. Similar to regular arguments, these need to be numpy objects, such as numpy.ndarray or numpy.int32, and so on.
Add shared memory arguments to the kernel.
- copy_texture_memory_args(texmem_args)¶
Adds texture memory arguments to the most recently compiled module.
- Parameters:
texmem_args (dict) – A dictionary containing the data to be passed to the device texture memory. See tune_kernel().
- kernel_finished()¶
Returns True if the kernel has finished, False otherwise.
- memcpy_dtoh(dest, src)¶
Perform a device to host memory copy.
- Parameters:
dest (numpy.ndarray) – A numpy array in host memory to store the data
src (pycuda.driver.DeviceAllocation) – A GPU memory allocation unit
- memcpy_htod(dest, src)¶
Perform a host to device memory copy.
- Parameters:
dest (pycuda.driver.DeviceAllocation) – A GPU memory allocation unit
src (numpy.ndarray) – A numpy array in host memory to store the data
- memset(allocation, value, size)¶
Set the memory in allocation to the value in value.
- Parameters:
allocation (pycuda.driver.DeviceAllocation) – A GPU memory allocation unit
value (a single 8-bit unsigned int) – The value to set the memory to
size (int) – The size of to the allocation unit in bytes
- ready_argument_list(arguments)¶
Ready argument list to be passed to the kernel, allocates gpu mem.
- Parameters:
arguments (list(numpy objects)) – List of arguments to be passed to the kernel. The order should match the argument list on the CUDA kernel. Allowed values are numpy.ndarray, and/or numpy.int32, numpy.float32, and so on.
- Returns:
A list of arguments that can be passed to an CUDA kernel.
- Return type:
list( pycuda.driver.DeviceAllocation, numpy.int32, … )
- run_kernel(func, gpu_args, threads, grid, stream=None)¶
Runs the CUDA kernel passed as ‘func’.
- Parameters:
func (pycuda.driver.Function) – A PyCuda kernel compiled for this specific kernel configuration
gpu_args (list( pycuda.driver.DeviceAllocation, numpy.int32, ...)) – A list of arguments to the kernel, order should match the order in the code. Allowed values are either variables in global memory or single values passed by value.
threads (tuple(int, int, int)) – A tuple listing the number of threads in each dimension of the thread block
grid (tuple(int, int)) – A tuple listing the number of thread blocks in each dimension of the grid
- start_event()¶
Records the event that marks the start of a measurement.
- stop_event()¶
Records the event that marks the end of a measurement.
- synchronize()¶
Halts execution until device has finished its tasks.
kernel_tuner.backends.cupy.CupyFunctions¶
- class kernel_tuner.backends.cupy.CupyFunctions(device=0, iterations=7, compiler_options=None, observers=None)¶
Class that groups the Cupy functions on maintains state about the device.
- __init__(device=0, iterations=7, compiler_options=None, observers=None)¶
Instantiate CupyFunctions object used for interacting with the CUDA device.
Instantiating this object will inspect and store certain device properties at runtime, which are used during compilation and/or execution of kernels by the kernel tuner. It also maintains a reference to the most recently compiled source module for copying data to constant memory before kernel launch.
- Parameters:
device (int) – Number of CUDA device to use for this context
iterations (int) – Number of iterations used while benchmarking a kernel, 7 by default.
- compile(kernel_instance)¶
Call the CUDA compiler to compile the kernel, return the device function.
- Parameters:
kernel_name (string) – The name of the kernel to be compiled, used to lookup the function after compilation.
kernel_string (string) – The CUDA kernel code that contains the function kernel_name
- Returns:
An CUDA kernel that can be called directly.
- Return type:
cupy.RawKernel
- copy_constant_memory_args(cmem_args)¶
Adds constant memory arguments to the most recently compiled module.
- Parameters:
cmem_args (dict( string: numpy.ndarray, ... )) – A dictionary containing the data to be passed to the device constant memory. The format to be used is as follows: A string key is used to name the constant memory symbol to which the value needs to be copied. Similar to regular arguments, these need to be numpy objects, such as numpy.ndarray or numpy.int32, and so on.
Add shared memory arguments to the kernel.
- copy_texture_memory_args(texmem_args)¶
Adds texture memory arguments to the most recently compiled module.
- Parameters:
texmem_args (dict) – A dictionary containing the data to be passed to the device texture memory. See tune_kernel().
- kernel_finished()¶
Returns True if the kernel has finished, False otherwise.
- memcpy_dtoh(dest, src)¶
Perform a device to host memory copy.
- Parameters:
dest (numpy.ndarray) – A numpy array in host memory to store the data
src (cupy.ndarray) – A GPU memory allocation unit
- memcpy_htod(dest, src)¶
Perform a host to device memory copy.
- Parameters:
dest (cupy.ndarray) – A GPU memory allocation unit
src (numpy.ndarray) – A numpy array in host memory to store the data
- memset(allocation, value, size)¶
Set the memory in allocation to the value in value.
- Parameters:
allocation (cupy.ndarray) – A GPU memory allocation unit
value (a single 8-bit unsigned int) – The value to set the memory to
size (int) – The size of to the allocation unit in bytes
- ready_argument_list(arguments)¶
Ready argument list to be passed to the kernel, allocates gpu mem.
- Parameters:
arguments (list(numpy objects)) – List of arguments to be passed to the kernel. The order should match the argument list on the CUDA kernel. Allowed values are numpy.ndarray, and/or numpy.int32, numpy.float32, and so on.
- Returns:
A list of arguments that can be passed to an CUDA kernel.
- Return type:
list( cupy.ndarray, numpy.int32, … )
- run_kernel(func, gpu_args, threads, grid, stream=None)¶
Runs the CUDA kernel passed as ‘func’.
- Parameters:
func (cupy.RawKernel) – A cupy kernel compiled for this specific kernel configuration
gpu_args (list( cupy.ndarray, numpy.int32, ...)) – A list of arguments to the kernel, order should match the order in the code. Allowed values are either variables in global memory or single values passed by value.
threads (tuple(int, int, int)) – A tuple listing the number of threads in each dimension of the thread block
grid (tuple(int, int)) – A tuple listing the number of thread blocks in each dimension of the grid
- start_event()¶
Records the event that marks the start of a measurement.
- stop_event()¶
Records the event that marks the end of a measurement.
- synchronize()¶
Halts execution until device has finished its tasks.
kernel_tuner.backends.nvcuda.CudaFunctions¶
- class kernel_tuner.backends.nvcuda.CudaFunctions(device=0, iterations=7, compiler_options=None, observers=None)¶
Class that groups the Cuda functions and it maintains state about the device.
- __init__(device=0, iterations=7, compiler_options=None, observers=None)¶
Instantiate CudaFunctions object used for interacting with the CUDA device.
Instantiating this object will inspect and store certain device properties at runtime, which are used during compilation and/or execution of kernels by the kernel tuner. It also maintains a reference to the most recently compiled source module for copying data to constant memory before kernel launch.
- Parameters:
device (int) – Number of CUDA device to use for this context
iterations (int) – Number of iterations used while benchmarking a kernel, 7 by default.
compiler_options – Compiler options for the CUDA runtime compiler
observers – List of Observer type objects
- compile(kernel_instance)¶
Call the CUDA compiler to compile the kernel, return the device function.
- Parameters:
kernel_name (string) – The name of the kernel to be compiled, used to lookup the function after compilation.
kernel_string (string) – The CUDA kernel code that contains the function kernel_name
- Returns:
A kernel that can be launched by the CUDA runtime
- Return type:
- copy_constant_memory_args(cmem_args)¶
Adds constant memory arguments to the most recently compiled module.
- Parameters:
cmem_args (dict( string: numpy.ndarray, ... )) – A dictionary containing the data to be passed to the device constant memory. The format to be used is as follows: A string key is used to name the constant memory symbol to which the value needs to be copied. Similar to regular arguments, these need to be numpy objects, such as numpy.ndarray or numpy.int32, and so on.
Add shared memory arguments to the kernel.
- copy_texture_memory_args(texmem_args)¶
Adds texture memory arguments to the most recently compiled module.
- Parameters:
texmem_args (dict) – A dictionary containing the data to be passed to the device texture memory. See tune_kernel().
- kernel_finished()¶
Returns True if the kernel has finished, False otherwise.
- static memcpy_dtoh(dest, src)¶
Perform a device to host memory copy.
- Parameters:
dest (numpy.ndarray) – A numpy array in host memory to store the data
src (cuda.CUdeviceptr) – A GPU memory allocation unit
- static memcpy_htod(dest, src)¶
Perform a host to device memory copy.
- Parameters:
dest (cuda.CUdeviceptr) – A GPU memory allocation unit
src (numpy.ndarray) – A numpy array in host memory to store the data
- static memset(allocation, value, size)¶
Set the memory in allocation to the value in value.
- Parameters:
allocation (cupy.ndarray) – A GPU memory allocation unit
value (a single 8-bit unsigned int) – The value to set the memory to
size (int) – The size of to the allocation unit in bytes
- ready_argument_list(arguments)¶
Ready argument list to be passed to the kernel, allocates gpu mem.
- Parameters:
arguments (list(numpy objects)) – List of arguments to be passed to the kernel. The order should match the argument list on the CUDA kernel. Allowed values are numpy.ndarray, and/or numpy.int32, numpy.float32, and so on.
- Returns:
A list of arguments that can be passed to an CUDA kernel.
- Return type:
list( pycuda.driver.DeviceAllocation, numpy.int32, … )
- run_kernel(func, gpu_args, threads, grid, stream=None)¶
Runs the CUDA kernel passed as ‘func’.
- Parameters:
func (cuda.CUfunction) – A CUDA kernel compiled for this specific kernel configuration
gpu_args (list( cupy.ndarray, numpy.int32, ...)) – A list of arguments to the kernel, order should match the order in the code. Allowed values are either variables in global memory or single values passed by value.
threads (tuple(int, int, int)) – A tuple listing the number of threads in each dimension of the thread block
grid (tuple(int, int)) – A tuple listing the number of thread blocks in each dimension of the grid
- set_sm_percentage(sm_percentage)¶
Set the active SM percentage
Create a CUDA green context owning ~`sm_percentage` of the device’s SMs and a stream bound to it. Kernels launched afterwards are restricted to that SM partition. Green contexts are cached in self.green_ctx_cache. The actual number of SMs in the partition may not exactly match the requested percentage. An observer may be used to query:
Currently assigned number of SMs: self.assigned_sm_count
Currently requested SM percentage: self.current_sm_percentage
Requires: CUDA >= 12.4 and a GPU that supports SM partitioning.
- start_event()¶
Records the event that marks the start of a measurement.
- stop_event()¶
Records the event that marks the end of a measurement.
- static synchronize()¶
Halts execution until device has finished its tasks.
kernel_tuner.backends.opencl.OpenCLFunctions¶
- class kernel_tuner.backends.opencl.OpenCLFunctions(device=0, platform=0, iterations=7, compiler_options=None, observers=None)¶
Class that groups the OpenCL functions on maintains some state about the device.
- __init__(device=0, platform=0, iterations=7, compiler_options=None, observers=None)¶
Creates OpenCL device context and reads device properties.
- Parameters:
device (int) – The ID of the OpenCL device to use for benchmarking
iterations (int) – The number of iterations to run the kernel during benchmarking, 7 by default.
- compile(kernel_instance)¶
Call the OpenCL compiler to compile the kernel, return the device function.
- Parameters:
kernel_name (string) – The name of the kernel to be compiled, used to lookup the function after compilation.
kernel_string (string) – The OpenCL kernel code that contains the function kernel_name
- Returns:
An OpenCL kernel that can be called directly.
- Return type:
pyopencl.Kernel
- copy_constant_memory_args(cmem_args)¶
This method must implement the allocation and copy of constant memory to the GPU.
This method must implement the dynamic allocation of shared memory on the GPU.
- copy_texture_memory_args(texmem_args)¶
This method must implement the allocation and copy of texture memory to the GPU.
- kernel_finished()¶
Returns True if the kernel has finished, False otherwise.
- memcpy_dtoh(dest, src)¶
Perform a device to host memory copy.
- Parameters:
dest (numpy.ndarray) – A numpy array in host memory to store the data
src (pyopencl.Buffer) – An OpenCL Buffer to copy data from
- memcpy_htod(dest, src)¶
Perform a host to device memory copy.
- Parameters:
dest (pyopencl.Buffer) – An OpenCL Buffer to copy data from
src (numpy.ndarray) – A numpy array in host memory to store the data
- memset(buffer, value, size)¶
Set the memory in allocation to the value in value.
- Parameters:
allocation (pyopencl.Buffer) – An OpenCL Buffer to fill
value (a single 32-bit int) – The value to set the memory to
size (int) – The size of to the allocation unit in bytes
- ready_argument_list(arguments)¶
Ready argument list to be passed to the kernel, allocates gpu mem.
- Parameters:
arguments (list(numpy objects)) – List of arguments to be passed to the kernel. The order should match the argument list on the OpenCL kernel. Allowed values are numpy.ndarray, and/or numpy.int32, numpy.float32, and so on.
- Returns:
A list of arguments that can be passed to an OpenCL kernel.
- Return type:
list( pyopencl.Buffer, numpy.int32, … )
- run_kernel(func, gpu_args, threads, grid)¶
Runs the OpenCL kernel passed as ‘func’.
- Parameters:
func (pyopencl.Kernel) – An OpenCL Kernel
gpu_args (list( pyopencl.Buffer, numpy.int32, ...)) – A list of arguments to the kernel, order should match the order in the code. Allowed values are either variables in global memory or single values passed by value.
threads (tuple(int, int, int)) – A tuple listing the number of work items in each dimension of the work group.
grid (tuple(int, int)) – A tuple listing the number of work groups in each dimension of the NDRange.
- start_event()¶
Records the event that marks the start of a measurement.
In OpenCL the event is created when the kernel is launched
- stop_event()¶
Records the event that marks the end of a measurement.
In OpenCL the event is created when the kernel is launched
- synchronize()¶
Halts execution until device has finished its tasks.
kernel_tuner.backends.compiler.CompilerFunctions¶
- class kernel_tuner.backends.compiler.CompilerFunctions(iterations=7, compiler_options=None, compiler=None, observers=None)¶
Class that groups the code for running and compiling C functions
- __init__(iterations=7, compiler_options=None, compiler=None, observers=None)¶
instantiate CFunctions object used for interacting with C code
- Parameters:
iterations (int) – Number of iterations used while benchmarking a kernel, 7 by default.
- cleanup_lib()¶
unload the previously loaded shared library
- compile(kernel_instance)¶
call the C compiler to compile the kernel, return the function
- Parameters:
kernel_instance (kernel_tuner.core.KernelInstance) – An object representing the specific instance of the tunable kernel in the parameter space.
- Returns:
An ctypes function that can be called directly.
- Return type:
ctypes._FuncPtr
- kernel_finished()¶
Returns True if the kernel has finished, False otherwise
C backend does not support asynchronous launches
- memcpy_dtoh(dest, src)¶
This method implements the semantic of a device to host copy for the Compiler backend. There is no actual copy from device to host happening, but host to host.
- Parameters:
dest (np.ndarray or cupy.ndarray) – A numpy or cupy array to store the data
src (Argument) – An Argument for some memory allocation
- memcpy_htod(dest, src)¶
There is no memcpy_htod implemented for the compiler backend.
- memset(allocation, value, size)¶
set the memory in allocation to the value in value
- Parameters:
allocation (Argument) – An Argument for some memory allocation unit
value (a single 8-bit unsigned int) – The value to set the memory to
size (int) – The size of to the allocation unit in bytes
- ready_argument_list(arguments)¶
ready argument list to be passed to the C function
- Parameters:
arguments (list(numpy or cupy objects)) – List of arguments to be passed to the C function. The order should match the argument list on the C function. Allowed values are np.ndarray, cupy.ndarray, and/or np.int32, np.float32, and so on.
- Returns:
A list of arguments that can be passed to the C function.
- Return type:
list(Argument)
- refresh_memory(_, arguments, should_sync)¶
Copy the preserved content of the output memory to used arrays.
- run_kernel(func, c_args, threads, grid, stream=None)¶
runs the kernel once, returns whatever the kernel returns
- Parameters:
func (ctypes._FuncPtr) – A C function compiled for this specific configuration
c_args (list(Argument)) – A list of arguments to the function, order should match the order in the code. The list should be prepared using ready_argument_list().
threads (any) – Ignored, but left as argument for now to have the same interface as Backend.
grid (any) – Ignored, but left as argument for now to have the same interface as Backend.
stream – Ignored, but left as argument for now to have the same interface as Backend.
- Returns:
A robust average of values returned by the C function.
- Return type:
float
- start_event()¶
Records the event that marks the start of a measurement
C backend does not use events
- stop_event()¶
Records the event that marks the end of a measurement
C backend does not use events
- synchronize()¶
Halts execution until device has finished its tasks
C backend does not support asynchronous launches
kernel_tuner.backends.hip.HipFunctions¶
- class kernel_tuner.backends.hip.HipFunctions(device=0, iterations=7, compiler_options=None, observers=None)¶
Class that groups the HIP functions and maintains state about the device.
- __init__(device=0, iterations=7, compiler_options=None, observers=None)¶
Instantiate HipFunctions object used for interacting with the HIP device.
Instantiating this object will inspect and store certain device properties at runtime, which are used during compilation and/or execution of kernels by the kernel tuner. It also maintains a reference to the most recently compiled source module for copying data to constant memory before kernel launch.
- Parameters:
device (int) – Number of HIP device to use for this context
iterations (int) – Number of iterations used while benchmarking a kernel, 7 by default.
- compile(kernel_instance)¶
Call the HIP compiler to compile the kernel, return the function.
- Parameters:
kernel_instance (kernel_tuner.core.KernelInstance) – An object representing the specific instance of the tunable kernel in the parameter space.
- Returns:
A HIP kernel function that can be called.
- Return type:
hipFunction_t
- copy_constant_memory_args(cmem_args)¶
Adds constant memory arguments to the most recently compiled module.
- Parameters:
cmem_args (dict(string: numpy.ndarray, ...)) – A dictionary containing the data to be passed to the device constant memory. The format to be used is as follows: A string key is used to name the constant memory symbol to which the value needs to be copied. Similar to regular arguments, these need to be numpy objects, such as numpy.ndarray or numpy.int32, and so on.
Add shared memory arguments to the kernel.
- copy_texture_memory_args(texmem_args)¶
Copy texture memory arguments. Not yet implemented.
- kernel_finished()¶
Returns True if the kernel has finished, False otherwise.
- memcpy_dtoh(dest, src)¶
Perform a device to host memory copy.
- Parameters:
dest (numpy.ndarray) – A numpy array in host memory to store the data
src (DeviceArray or int) – A GPU memory allocation unit
- memcpy_htod(dest, src)¶
Perform a host to device memory copy.
- Parameters:
dest (DeviceArray or int) – A GPU memory allocation unit
src (numpy.ndarray) – A numpy array in host memory to copy from
- memset(allocation, value, size)¶
Set the memory in allocation to the value in value.
- Parameters:
allocation (DeviceArray or int) – A GPU memory allocation (DeviceArray)
value (int (8-bit unsigned)) – The value to set the memory to
size (int) – The size of to the allocation unit in bytes
- ready_argument_list(arguments)¶
Ready argument list to be passed to the HIP function.
- Parameters:
arguments (list(numpy objects)) – List of arguments to be passed to the HIP function. The order should match the argument list on the HIP function. Allowed values are np.ndarray, and/or np.int32, np.float32, and so on.
- Returns:
List of arguments to be passed to the HIP function.
- Return type:
list
- run_kernel(func, gpu_args, threads, grid, stream=None)¶
Runs the HIP kernel passed as ‘func’.
- Parameters:
func (hipFunction_t) – A HIP kernel compiled for this specific kernel configuration
gpu_args (list) – List of arguments to pass to the kernel. Can be DeviceArray objects or ctypes values
threads (tuple(int, int, int)) – A tuple listing the number of threads in each dimension of the thread block
grid (tuple(int, int, int)) – A tuple listing the number of thread blocks in each dimension of the grid
- start_event()¶
Records the event that marks the start of a measurement.
- stop_event()¶
Records the event that marks the end of a measurement.
- synchronize()¶
Halts execution until device has finished its tasks.
Util Functions¶
kernel_tuner.util¶
Module for kernel tuner utility functions.
- class kernel_tuner.util.CompilationFailedConfig¶
- class kernel_tuner.util.ConstraintLambdaTransformer(dict_arg_name)¶
Replaces any NAME[‘string’] subscript with just ‘string’, if NAME matches the lambda argument name.
- class kernel_tuner.util.ErrorConfig¶
- class kernel_tuner.util.InvalidConfig¶
- class kernel_tuner.util.NpEncoder(*, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, sort_keys=False, indent=None, separators=None, default=None)¶
Class we use for dumping Numpy objects to JSON.
- default(obj)¶
Implement this method in a subclass such that it returns a serializable object for
o, or calls the base implementation (to raise aTypeError).For example, to support arbitrary iterators, you could implement default like this:
def default(self, o): try: iterable = iter(o) except TypeError: pass else: return list(iterable) # Let the base class default method raise the TypeError return JSONEncoder.default(self, o)
- class kernel_tuner.util.RuntimeFailedConfig¶
- exception kernel_tuner.util.SkippableFailure¶
Exception used to raise when compiling or launching a kernel fails for a reason that can be expected.
- exception kernel_tuner.util.StopCriterionReached¶
Exception thrown when a stop criterion has been reached.
- class kernel_tuner.util.Timer¶
Measures elapsed wall-clock time.
- get() float¶
Elapsed time in seconds.
- get_and_reset() float¶
Elapsed time in seconds, then reset.
- reset()¶
Reset the timer to now.
- kernel_tuner.util.check_argument_list(kernel_name, kernel_string, args)¶
Raise an exception if kernel arguments do not match host arguments.
- kernel_tuner.util.check_argument_type(dtype, kernel_argument)¶
Check if the numpy.dtype matches the type used in the code.
- kernel_tuner.util.check_matching_problem_size(cached_problem_size, problem_size)¶
Check the if requested problem size matches the problem size in the cache.
- kernel_tuner.util.check_restriction(restrict, params: dict) bool¶
Check whether a configuration meets a search space restriction.
- kernel_tuner.util.check_restrictions(restrictions, params: dict, verbose: bool) bool¶
Check whether a configuration meets the search space restrictions.
- kernel_tuner.util.check_result_type(r)¶
Check if the result has the right format.
- kernel_tuner.util.check_thread_block_dimensions(params, max_threads, block_size_names=None)¶
Check on maximum thread block dimensions.
- kernel_tuner.util.check_tune_params_list(tune_params, observers, simulation_mode=False)¶
Raise an exception if a tune parameter has a forbidden name.
- kernel_tuner.util.compile_restrictions(restrictions: list, tune_params: dict, monolithic=False, format=None) list[tuple[str | LambdaType, list[str], str | None]]¶
Parses restrictions from a list of strings into a list of strings or Functions and parameters used and source, or a single Function if monolithic is true.
- kernel_tuner.util.config_valid(config, tuning_options, max_threads)¶
Combines restrictions and a check on the max thread block dimension to check config validity.
- kernel_tuner.util.convert_constraint_lambdas(restrictions)¶
Extract and convert all constraint lambdas from the restrictions
- kernel_tuner.util.convert_constraint_restriction(restrict: Constraint)¶
Convert the python-constraint to a function for backwards compatibility.
- kernel_tuner.util.copy_without_benchmark_timings(result: dict) dict¶
Returns a new dict where all the timing information related to benchmarking a single configurations have been disable.
- kernel_tuner.util.correct_open_cache(cachefile, open_cache=True)¶
If cache file was not properly closed, pretend it was properly closed.
- kernel_tuner.util.delete_temp_file(filename)¶
Delete a temporary file, don’t complain if no longer exists.
- kernel_tuner.util.detect_language(kernel_string)¶
Attempt to detect language from the kernel_string.
- kernel_tuner.util.dump_cache(obj: str, tuning_options)¶
Dumps a string in the cache, this omits the several checks of store_cache() to speed up the process - with great power comes great responsibility!
- kernel_tuner.util.get_all_lambda_asts(func)¶
Extracts the AST nodes of all lambda functions defined on the same line as func.
- Parameters:
func – A lambda function object.
- Returns:
A list of all ast.Lambda node objects on the line where func is defined.
- Raises:
ValueError – If the source can’t be retrieved or no lambda is found.
- kernel_tuner.util.get_best_config(results, objective, objective_higher_is_better=False)¶
Returns the best configuration from a list of results according to some objective.
- kernel_tuner.util.get_config_string(params, keys=None, units=None)¶
Return a compact string representation of a measurement.
- kernel_tuner.util.get_grid_dimensions(current_problem_size, params, grid_div, block_size_names)¶
Compute grid dims based on problem sizes and listed grid divisors.
- kernel_tuner.util.get_instance_string(params)¶
Combine the parameters to a string mostly used for debug output use of dict is advised.
- kernel_tuner.util.get_interval(a: list)¶
Checks if an array can be an interval. Returns (start, end, step) if interval, otherwise None.
- kernel_tuner.util.get_kernel_string(kernel_source, params=None)¶
Retrieve the kernel source and return as a string.
This function processes the passed kernel_source argument, which could be a function, a string with a filename, or just a string with code already.
If kernel_source is a function, the function is called with instance parameters in ‘params’ as the only argument.
If kernel_source looks like filename, the file is read in, but if the file does not exist, it is assumed that the string is not a filename after all.
- Parameters:
kernel_source (string or callable) – One of the sources for the kernel, could be a function that generates the kernel code, a string or Path containing a filename that points to the kernel source, or just a string that contains the code.
params – Dictionary containing the tunable parameters for this specific kernel instance, only needed when kernel_source is a generator.
- Returns:
A string containing the kernel code.
- Return type:
string
- kernel_tuner.util.get_objective_defaults(objective, objective_higher_is_better)¶
Use time as default objective and infer objective_higher_is_better for known objectives.
- kernel_tuner.util.get_problem_size(problem_size, params)¶
Compute current problem size.
- kernel_tuner.util.get_result_cost(result: dict, objectives: list[str], objective_higher_is_better: list[bool]) list[float]¶
Returns the cost of a result, taking the objective directions into account.
- kernel_tuner.util.get_smem_args(smem_args, params)¶
Return a dict with kernel instance specific size.
- kernel_tuner.util.get_temp_filename(suffix=None)¶
Return a string in the form of temp_X, where X is a large integer.
- kernel_tuner.util.get_thread_block_dimensions(params, block_size_names=None)¶
Thread block size from tuning params, currently using convention.
- kernel_tuner.util.get_total_timings(results, env, overhead_time)¶
Sum all timings and put their totals in the env.
- kernel_tuner.util.looks_like_a_filename(kernel_source)¶
Attempt to detect whether source code or a filename was passed.
- kernel_tuner.util.normalize_verify_function(v)¶
Normalize a user-specified verify function.
The user-specified function has two required positional arguments (answer, result_host), and an optional keyword (or keyword-only) argument atol. We normalize it to always accept an atol keyword argument.
Undefined behaviour if the passed function does not match the required signatures.
- kernel_tuner.util.parse_restrictions(restrictions: list[str], tune_params: dict, monolithic=False, format=None) list[tuple[Constraint | str, list[str]]]¶
Parses restrictions from a list of strings into compilable functions and constraints, or a single compilable function (if monolithic is True). Returns a list of tuples of (strings or constraints) and parameters.
- kernel_tuner.util.prepare_kernel_string(kernel_name, kernel_string, params, grid, threads, block_size_names, lang, defines)¶
Prepare kernel string for compilation.
Prepends the kernel with a series of C preprocessor defines specific to this kernel instance:
the thread block dimensions
the grid dimensions
tunable parameters
- Parameters:
kernel_name (string) – Name of the kernel.
kernel_string (string) – One of the source files of the kernel as a string containing code.
params (dict) – A dictionary containing the tunable parameters specific to this instance.
grid (tuple(x,y,z)) – A tuple with the grid dimensions for this specific instance.
threads (tuple(x,y,z)) – A tuple with the thread block dimensions for this specific instance.
block_size_names (tuple(string)) – A tuple with the names of the thread block dimensions used in the code. By default this is [“block_size_x”, …], but the user may supply different names if they prefer.
defines (dict or None) – A dict that describes the variables that should be defined as preprocessor macros. Each keys should be the variable names and each value is either a string or a function that returns a string. If None, each tunable parameter is defined as preprocessor macro instead.
- Returns:
A string containing the source code made specific to this kernel instance.
- Return type:
string
- kernel_tuner.util.print_config(config, tuning_options, runner)¶
Print the configuration string with tunable parameters and benchmark results.
- kernel_tuner.util.print_config_output(tune_params, params, quiet, metrics, units)¶
Print the configuration string with tunable parameters and benchmark results.
- kernel_tuner.util.process_cache(cachefile, kernel_options, tuning_options, runner)¶
Cache file for storing tuned configurations.
the cache file is stored using JSON and uses the following format:
{ device_name: "name of device" kernel_name: "name of kernel" problem_size: (int, int, int) tune_params_keys: list tune_params: cache: { "x1,x2,..xN": {"block_size_x": x1, ..., time=0.234342}, "y1,y2,..yN": {"block_size_x": y1, ..., time=0.134233}, } }
The last two closing brackets are not required, and everything should work as expected if these are missing. This is to allow to continue from an earlier (abruptly ended) tuning session.
- kernel_tuner.util.process_metrics(params, metrics)¶
Process user-defined metrics for derived benchmark results.
Metrics must be a dictionary to support composable metrics. The dictionary keys describe the name given to this user-defined metric and will be used as the key in the results dictionaries return by Kernel Tuner. The values describe how to calculate the user-defined metric, using either a string expression in which the tunable parameters and benchmark results can be used as variables, or as a function that accepts a dictionary as argument.
Example: metrics = dict() metrics[“x”] = “10000 / time” metrics[“x2”] = “x*x”
Note that the values in the metric dictionary can also be functions that accept params as argument.
Example: metrics = dict() metrics[“GFLOP/s”] = lambda p : 10000 / p[“time”]
- Parameters:
params (dict) – A dictionary with tunable parameters and benchmark results.
metrics (dict) – A dictionary with user-defined metrics that can be used to create derived benchmark results.
- Returns:
An updated params dictionary with the derived metrics inserted along with the benchmark results.
- Return type:
dict
- kernel_tuner.util.read_cache(cachefile, open_cache=True)¶
Read the cachefile into a dictionary, if open_cache=True prepare the cachefile for appending.
- kernel_tuner.util.read_file(filename)¶
Return the contents of the file named filename or None if file not found.
- kernel_tuner.util.replace_param_occurrences(string: str, params: dict)¶
Replace occurrences of the tuning params with their current value.
- kernel_tuner.util.setup_block_and_grid(problem_size, grid_div, params, block_size_names=None)¶
Compute problem size, thread block and grid dimensions for this kernel.
- kernel_tuner.util.store_cache(key, params, cachefile, cache)¶
Stores a new entry (key, params) to the cachefile.
- kernel_tuner.util.unparse_constraint_lambda(lambda_ast)¶
Parse the lambda function to replace accesses to tunable parameter dict Returns string body of the rewritten lambda function
- kernel_tuner.util.write_file(filename, string)¶
Dump the contents of string to a file called filename.